Actualidad UAM

Los científicos Eugenio Coronado y Pedro Miguel Echenique, investidos doctores ‘honoris causa’ por la UAM
La rectora Amaya Mendikoetxea ha presidido la solemne ceremonia en la que los dos profesores se han incorporado al Colegio de Doctores y Doctoras de la Universidad Autónoma de Madrid. Al acto, "una gran fiesta de la Ciencia", en palabras de la rectora, ha asistido una amplia representación de la comunidad universitaria.

Los seis rectores de la CRUMA reivindican el papel crucial de las universidades públicas en el progreso económico y social
Los seis rectores de la CRUMA reivindican el papel crucial de las universidades públicas en el progreso económico y social
La UAM celebra la ‘Semana de las Lenguas’, del 22 al 26 de abril
La UAM celebra la ‘Semana de las Lenguas’, del 22 al 26 de abril
Un equipo de estudiantes de la UAM gana la final absoluta de la ‘European Law Moot Court Competition’ en Luxemburgo
Un equipo de estudiantes de la UAM gana la final absoluta de la ‘European Law Moot Court Competition’ en Luxemburgo
La UAM sitúa siete áreas en el top 100 mundial del 'Ranking QS by Subject 2024'
La UAM sitúa siete áreas en el top 100 mundial del 'Ranking QS by Subject 2024'COMUNICADOS
Declaración del Día Internacional de la Mujer y la Niña en la Ciencia
11F: Mujer y Niña en la Ciencia 2024
Por la Paz en Oriente Próximo
Declaración del Consejo de Gobierno por la Paz en Oriente Próximo
Crue rechaza la escalada bélica en Oriente Próximo y traslada su solidaridad a las comunidades universitarias y científicas de Israel y Palestina
CRUE sobre Oriente Próximo
Noticias científicas

Ciencia UAM en Casa de Fieras: Figuras divinas, heroicas y monstruosas. Mitología clásica en la cultura de masas contemporánea.
La Biblioteca Pública Eugenio Trías continúa con la VII Edición de Ciencia UAM en Casa de Fieras, sesiones en las que diferentes investigadores de la Universidad Autónoma de Madrid realizarán charlas informales, acercando así su trabajo científico al público general fuera del ámbito académico, en la antigua Casa de Fieras del Parque del Retiro de Madrid.
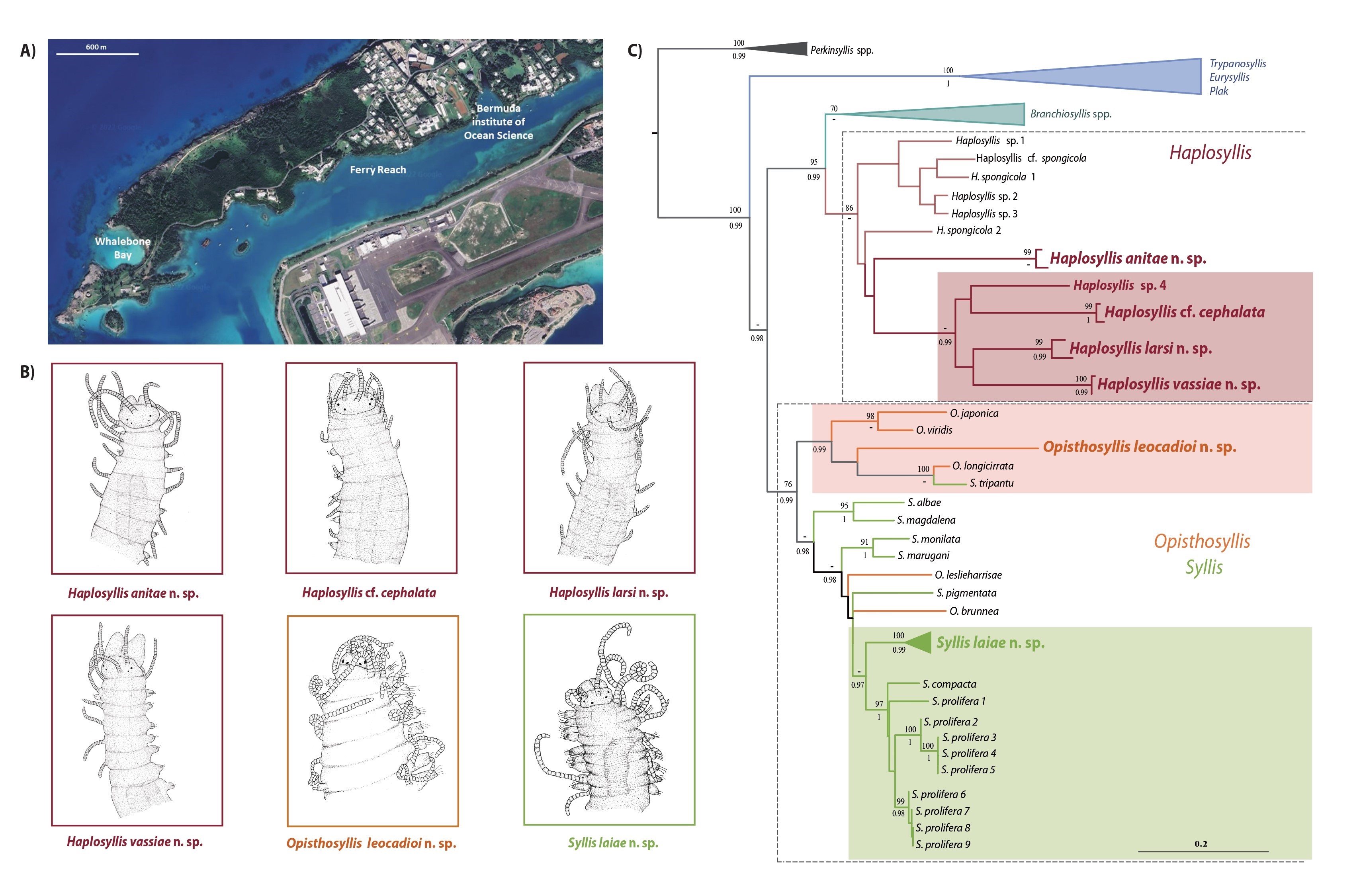
Descubiertas cinco nuevas especies de gusanos marinos en el Archipiélago de Bermuda
Descubiertas cinco nuevas especies de gusanos marinos en el Archipiélago de Bermuda
Nuevo modelo de ratón de la enfermedad fenilcetonuria
Nuevo modelo de ratón de la enfermedad fenilcetonuria
Cuaderno 210: El espectro de Marie Curie de la UAM al Círculo de Bellas Artes
Cuaderno 210: El espectro de Marie Curie de la UAM al Círculo de Bellas Artes
Identifican tres grupos de riesgo de suicidio durante la pandemia
Identifican tres grupos de riesgo de suicidio durante la pandemia
La UAM ante las crisis humanitarias

AGENDA UAM
Consulta las Agendas de los centros del Campus UAM-CSIC

Conoce los datos de la UAM, la universidad donde quieres estudiar

Cursos de Corta Duración
Consulta la oferta de Cursos de Corta Duración de la UAM que se impartirán hasta el mes de julio. Pensados para quienes buscan completar su formación.
![Infografía titulada Des[con]ecta la luz; [con]ecta con el planeta, que incluye recomendaciones para mejorar la eficiencia energética entre los usuarios, en los edificios y el campus](https://www.uam.es/uam/media/img/1606928370518/infografia-consumo-19-5-23.svg)
[CON]ecta con el planeta
Colabora con nosotros en la campaña 'Des[CON]ecta la luz; [CON]ecta con el planeta', una iniciativa de la UAM para mejorar la eficiencia energética en sus campus y edificios. El Plan elaborado incluye recomendaciones que todos podemos adoptar para que la universidad sea un entorno cada vez más verde y sostenible. ¡La suma de pequeños gestos puede marcar una gran diferencia!